|
| Google翻譯在中國惹來批評。 |
一篇號召網民“抵制Google翻譯工具”的帖子在著名網絡論壇“天涯雜談”上出現。帖子指責Google的翻譯工具出現離奇的“張冠李戴”現象,甚至有傷害中國人感情的嫌疑。那麼,Google是有意為之還是純屬巧合?
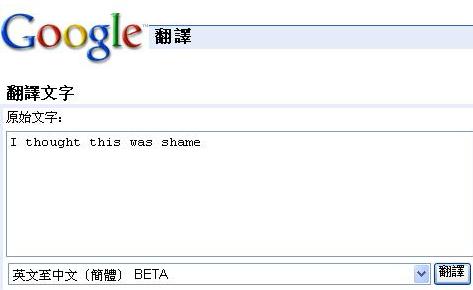
部分網民表示,Google網站的自動翻譯工具存在嚴重問題。該網民在“天涯雜談”發帖,對Google的不正確翻譯列舉了一些例子,如“I thought this was shame”(我認為這是恥辱)被譯為“我認為這是中國的恥辱”;出現“f”開頭的英文臟話時,Google將其離奇地譯為“我認為這是中國運動員良好”。
有網友因此質疑,為什麼出現一些“臟話”時,Google就會把它自動翻譯成與中國相關的內容?一些網友在看過這篇帖子後,回帖時顯得比較激動。
了解到這一情況後,記者親身體驗了Google的翻譯引擎。帖子上描述的幾個例子在得到核實的同時,記者發現確實有一些翻譯欠妥,但並非所有古怪的翻譯都把“中國”與貶義詞擺放在一起。比如“I thought this was glory”(我認為這是榮耀)的翻譯結果是“我認為這是中國的榮耀”。這個例子至少可以表明,這些錯誤翻譯並非有意針對中國人。
而輸入中文“壞學生”,翻譯出來的英文卻是“good students”(好學生),完全相反的意思讓人懷疑這是否是Google程序設計者的“惡搞”。
那麼,這一系列的“張冠李戴”現象究竟原因何在?Google中國公司委托奧美公關相關人士試圖向記者說明翻譯引擎的運作原理。
“我們已經收到了網友的投訴。”
該人士表示,Google翻譯引擎的運行原理是通過搜索大量的雙語網頁內容,將其作為資料庫,然後由電腦自動選取最常見的詞與詞的對應,最後給出翻譯結果。當中既不存在、也無法實施人工幹預。“機器不比人腦,不可能帶有那麼多感情因素來翻譯的。”他強調。對於“天涯雜談”上舉的例子,他表示這是個案,可能在歷史資料中,相關詞語偶然出現了一些關聯性,導致了Google翻譯工具的錯誤。所以,他希望網民用較為理性的思維來看待這個現象。
該人士還舉例說,同樣通過Google的引擎,諸如“兩國關系源遠流長”的外交詞匯翻譯得最準確。這正是因為Google已經將聯合國的多語言官方文檔納入其資料庫。
對網友的投訴,Google會怎樣應對?奧美公關人士稱,目前Google能夠做的,只能是加速改進並開發翻譯工具的智能,從基礎領域促進翻譯工具升級,但無法立即人工幹預這些“個例”。這一改良工作一直在進行中。
他強調,發生這樣的翻譯問題,自己作為一個中國人也感到相當遺憾。由於改建資料庫的工程相當浩大,所以這些不恰當的翻譯在短時間內或許還會在翻譯工具上出現。同時,由於英語是目前網絡上最為流通的語言,過多的網頁資料會影響雙向翻譯的匹配度,所以中英翻譯一直屬於Google一個較弱的環節。(來源:新聞晨報) |